
Künstliche Intelligenz (KI) ist heutzutage in aller Munde und wird oft im Zusammenhang mit effizienterem und schnellerem Arbeiten genannt. Dennoch stehen Systeme wie ChatGPT oft in der Kritik. Antworten seien falsch, Fragen würden aufgrund restriktiver Filter nicht beantwortet oder Fakten gar erfunden – die KI schaffe sich ihre ganz eigene Realität.
In der Softwareindustrie spielt die Sicherstellung von Qualität und Funktionalität eine wichtige Rolle. Fehler sollen schnell gefunden und behoben werden, möglichst noch bevor das Produkt den Endkunden erreicht. Dafür ist es wichtig, Software auf Herz und Nieren zu testen. Aber funktioniert das auch bei KI? Können KI-Systeme getestet werden und wenn ja, wie? In dieser Blogreihe gehe ich diesen Fragen auf die Spur und berichte von meinen Erkenntnissen rund um das Thema „Testen von KI“.
Aller Anfang ist … erstaunlich intuitiv?
Der Einstieg in die Welt der KI war aufgrund der Vielfalt an Systemen und Schwerpunkten nicht gerade einfach. Bisher hatte ich noch keine großen Berührungspunkte mit dem Thema. Meine Erfahrungen beschränkten sich bislang nur auf die Generierung von Bildern mit „Midjourney“, einfache Chatbot-Interaktionen mit „ChatGPT“ und die Nutzung von „Google Translate“ zur Übersetzung von Texten. Wo fängt man also am besten an und wo setzt man sich selbst die Grenzen? Die Gefahr ist groß, sich schnell in Themen zu verlieren, die zwar sehr interessant klingen, aber viel Zeit kosten, um zum Ziel zu kommen.
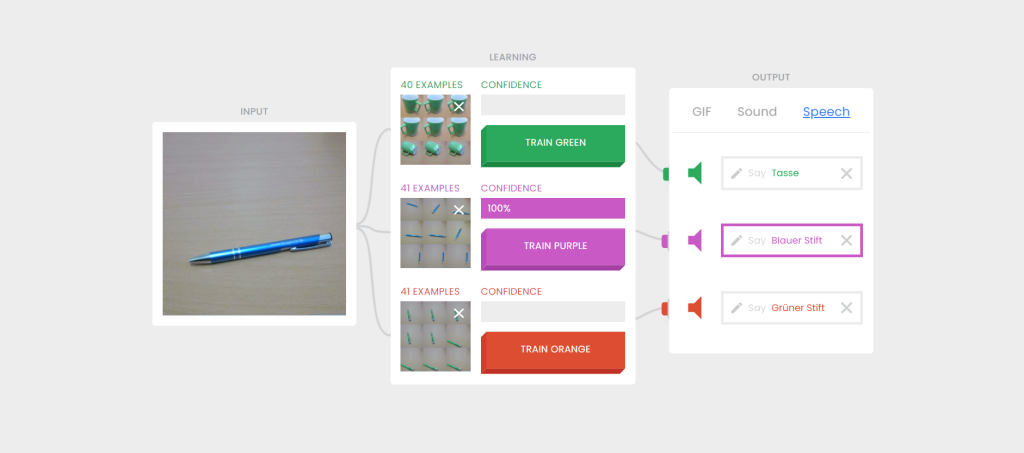
Zunächst galt es, ein grundlegendes Verständnis für die Funktionsweise von KI-Systemen aufzubauen und dieses Wissen Schritt für Schritt zu vertiefen. Die erste Anlaufstelle dafür war die „Teachable Machine“, mit der man seine eigene KI für die Bildklassifizierung erstellen kann. Das funktionierte sogar erstaunlich einfach und sehr intuitiv, auch ohne tiefere mathematische Kenntnisse. Es reichte, einen Gegenstand in die Kamera des Smartphones oder Laptops zu halten und per Knopfdruck auf der Weboberfläche verschiedene Bilder der Objekte aufzunehmen. Mit einem jeweils eigenen Trainingsset für Kugelschreiber, Kaffeetasse und Kopfhörer konnte die KI dann in Echtzeit zwischen den Gegenständen unterscheiden, die ich nur noch in die Kamera halten musste.
Ziel des maschinellen Lernens (engl. „machine learning“) ist es, aus Eingabedaten sinnvolle Zusammenhänge zu erkennen und daraus Regeln abzuleiten. Mit diesen Regeln kann ein System dann bei der Eingabe neuer, unbekannter Daten Trends erkennen, Daten klassifizieren oder Vorhersagen treffen. So wird im Beispiel der Teachable Machine eine auf dem Kopf stehende Kaffeetasse trotzdem richtig klassifiziert, obwohl sie nicht mehr den Daten entspricht, mit denen das System ursprünglich trainiert wurde.
Nachdem die ersten Experimente mit der Bildklassifizierungs-KI bereits vielversprechende und vor allem aber sehr anschauliche Ergebnisse lieferten, stand als nächstes Ziel auf der Agenda, ein ähnliches System auf einer eigenen Maschine zu implementieren. Glücklicherweise hatten die Entwickler der Teachable Machine eine ältere Version des Systems quelloffen auf GitHub veröffentlicht. Auch wenn es sich dabei um die archivierte Urversion handelt und die Funktionen recht einfach gehalten sind, war ein Blick in den Programmcode schon recht aufschlussreich. So werden die Bilder lokal auf der Maschine mittels Tensorflow trainiert. Eine Kommunikation mit anderen Diensten findet nicht statt.
Bildklassifizierung – was muss beachtet werden?
Das eigene System steht und liefert auch erste Ergebnisse. Im Test ist sich die KI sogar bis zu 95 Prozent sicher, dass es sich bei dem erkannten Objekt auch um das gezeigte handelt. In anderen Fällen werden die Objekte jedoch falsch klassifiziert. Aus einer Kaffeetasse wird plötzlich ein Kugelschreiber und in einem anderen Fall kann die KI die Gegenstände nicht mehr klar voneinander unterscheiden. Wie kann das passieren?
Bei der Erstellung der Trainingsdaten haben sich einige wichtige Merkmale herauskristallisiert:
- Der Hintergrund im Bild sollte möglichst gleich bleiben. Ein Stift, der auf dem Schreibtisch liegt und im Bild zu sehen ist, stellt dabei kein Problem dar. Vorausgesetzt, er ist auch in allen anderen Bildern und später in der Live-Webcam an der gleichen Stelle zu sehen.
- Das Objekt wird mit höherer Wahrscheinlichkeit erkannt, wenn es aus verschiedenen Perspektiven aufgenommen wird. Dabei hilft es beispielsweise, die Kaffeetasse so zu drehen, dass neben der Vorder- und Rückseite auch der Tassenboden, die Innenseite sowie auch mehrere seitliche und gedrehte Ansichten aufgenommen werden. Je mehr Trainingsdaten, desto besser das Ergebnis.
- Ein weiterer wichtiger Faktor waren Störungen. Hier reichte es bereits aus, wenn Körperteile wie Arme, Gesicht oder Oberkörper während der Aufnahme im Bild zu sehen waren. Die Klassifizierung funktionierte dann weniger zuverlässig.
- Auch Form und Farbe der Objekte sollten berücksichtigt werden. Während das System eine grüne Tasse sehr gut von einem blauen Stift unterscheiden kann, ist die Erkennung eines grünen Kugelschreibers schlechter als die eines blauen.
KI im Selbststudium
Nachdem ich die ersten Eindrücke durch die Interaktion mit KI gesammelt hatte, wollte ich das Thema vertiefen. Wie genau funktioniert KI aus technischer Sicht? Wie werden KIs erstellt? Was muss man dabei beachten? Und vor allem: Wie kann man KI testen?
Ein sehr hilfreicher und wichtiger Begleiter auf dem Weg, KI testen zu können, war das c’t-Sonderheft „KI-Praxis“ (2023/24). Dadurch konnte ich die grundlegenden Inhalte zum Thema KI besser verstehen und direkt mit meinen praktischen Erfahrungen mit der Bildklassifikations-KI verknüpfen. Doch wie geht es weiter?
Das ISTQB „Certified Tester Foundation Level“ ist ein internationaler Standard und eine anerkannte Grundlage im Bereich des Softwaretestens. Obwohl die darin enthaltenen Begriffe und Konzepte generell auf alle Softwareprojekte anwendbar sind, geht das ISTQB noch einen Schritt weiter. Der Lehrplan für den „Certified Tester AI Testing“ zielt darauf ab, den eigenen Horizont in Bezug auf künstliche Intelligenz zu erweitern, insbesondere in Bezug auf das Testen von KI-Systemen – also genau das, was ich brauche. So konnte ich durch die Lerninhalte ein Grundverständnis für die verschiedenen Testmethoden, Qualitätsmerkmale und Risikoaspekte aufbauen, die für das Testen von KI-Systemen besonders wichtig sind.
Das nächste große Ziel war gesetzt und der Plan war, einen Abnahmetest für ein KI-System mit Schwerpunkt auf KI-Merkmalen zu entwickeln. Die nächsten Schritte waren, das Gelernte anzuwenden und mehrere KI-Systeme mit vortrainierten Modellen zu vergleichen. Doch genau hier tauchte das erste Problem auf. Eine Abnahme des Systems ist nur möglich, wenn ein bereits trainiertes Modell vorliegt. Die aufgestellte „Teachable Machine“ verfügte jedoch über keine Funktion, mit der aufgenommene Bilder und trainierte Modelle gespeichert und wieder aufgerufen werden können. Somit war es nicht möglich, das System in einen Startzustand zu versetzen, von dem aus zukünftige Tests unter gleichen Bedingungen wiederholt werden können. Andererseits konnte ich kein ähnlich funktionierendes KI-System finden, mit dem ein aussagekräftiger Vergleich möglich gewesen wäre. Ein Tapetenwechsel war also notwendig.
Der Weg zum eigenen KI-Übersetzer
Mit den rasanten technologischen Fortschritten hat die maschinelle Übersetzung einen wichtigen Meilenstein erreicht. Vor zehn Jahren stand ich maschinellen Übersetzern eher skeptisch gegenüber. Die Übersetzungsqualität des Google Übersetzers war nicht überzeugend und die Einsatzmöglichkeiten des Systems beschränkten sich auf eine einfache Weboberfläche. Heute sollen die Übersetzungen teilweise so gut sein, dass sie von einer menschlichen Übersetzung nicht mehr zu unterscheiden sind. Aber stimmt das wirklich?
Für die weitere Analyse habe ich mich zunächst auf zwei unterschiedliche Übersetzungssysteme konzentriert: DeepL und Libre Translate. Beide sind im Kern maschinelle Übersetzungssysteme (engl. „machine translation“). Während Libre Translate als quelloffenes System auf OpenNMT setzt, sitzt man bei DeepL vor verschlossenen Türen – das Unternehmen gibt nur wenig darüber preis, wie das System im Hintergrund arbeitet. Grund genug, die beiden Systeme genauer unter die Lupe zu nehmen und diese auf Herz und Nieren zu testen.
Nachdem die eigene Instanz von Libre Translate schnell eingerichtet war, stellte sich ebenso schnell die Frage, wie man das System am besten testen könnte. Ein intuitiver Ansatz wäre sicherlich, einen gegebenen Text in eine andere Sprache übersetzen zu lassen und diese Übersetzung dann wieder zurück in die Ausgangssprache zu übersetzen – ein Hin- und Herübersetzen sozusagen. Auf diese Weise könnte man prüfen, wie groß die Unterschiede zwischen dem Originaltext und dem zweimal übersetzten Text sind, oder? Leider nicht. Denn anstatt ein einzelnes System zu evaluieren, würde man zwei Systeme evaluieren, die unabhängig voneinander arbeiten – die Übersetzung von Sprache A nach Sprache B und die Rückübersetzung von Sprache B nach Sprache A. Daher ist dieser Ansatz nicht geeignet, um die Übersetzungsqualität zu evaluieren.
Eine andere Möglichkeit wäre die Bewertung der Übersetzungsqualität durch menschliche Übersetzer, Experten mit mehrjähriger Erfahrung in diesem Bereich. Die Texte könnten dann von den Experten auf verschiedene Merkmale hin untersucht werden.
- Wie gut ist die Qualität der Übersetzung?
- Wie viel von der Bedeutung des Originaltexts bleibt in der Übersetzung erhalten?
- Wie verständlich ist die Übersetzung?
- Gibt es fehlende Wörter oder falsche Wortfolgen in der Übersetzung?
Das Hauptproblem bei der Beantwortung dieser Fragen ist jedoch, dass sie zum Teil einer subjektiven bewertung unterliegen – standardisierte Metriken müssen erst mit den Experten entwickelt werden. Selbst dann ist die Bewertung meist subjektiv und eine kostspielige Angelegenheit.
Eine weniger kostspielige und wesentlich zuverlässigere Methode ist die Verwendung maschinell ausgewerteter Metriken. Eine der ersten Metriken dafür war die „Bilingual Evaluation Understudy“, kurz BLEU. Diese Metrik betrachtet die Übereinstimmung zwischen maschinellen und menschlichen Ergebnissen, sofern eine ausreichend große Menge an menschlich generierten Datensätzen zur Verfügung steht. Je näher die maschinelle Übersetzung an der professionellen menschlichen Übersetzung liegt, desto höher ist die Bewertung der Qualität.
Ein kurzer Ausblick
Nach dieser Einführung in die Welt des KI-Testens werden in den folgenden Kapiteln die vorgestellten Systeme genauer betrachtet, insbesondere im Hinblick auf die KI-spezifischen ISTQB-Merkmale. Neben den oben genannten Metriken werde ich weitere Testmethoden und Qualitätsmerkmale näher betrachten. In einer umfassenden Risikoanalyse werden zudem mögliche Risiken und Probleme der Systeme sowie deren Lösungsansätze aus der Sicht des Testings vorgestellt – immer mit dem Ziel vor Augen, einen allgemeinen Abnahmetest für KI-unterstützte Übersetzer zu entwerfen.

