
(Docker) Container werden meist zu einem bestimmten Zweck beziehungsweise für eine bestimmte Anwendung erstellt, also etwa für einen Webserver oder eine Datenbank. Komplexe Anwendungen wie Web-Applikationen benötigen im Normalfall mehrere Server-Dienste, zum Beispiel einen Webserver für statischen Content, einen Java-Application-Server für die Businesslogik und eine Datenbank zur Persistierung.
Auf den ersten Blick gibt es zwei Möglichkeiten, eine Entwicklungs- oder Produktionsumgebung für die benötigten Komponenten zu erstellen.
So kann per docker run jeder Container separat gestartet werden, eventuell auch per Batch-Skript. Das Batch-Skript ist allerdings betriebssystemabhängig und skaliert nicht gut, da weitere Ressourcen nur durch Anpassung des Batch-Skriptes hinzugefügt können. Auch beim Beenden der Laufzeitumgebung muss jeder Container einzeln gestoppt werden. Häufig müssen Komponenten zudem in einer bestimmten Reihenfolge gestartet werden (z.B. Datenbank vor Applikationsserver). docker run ist allerdings nicht in der Lage zu erkennen, ob ein Container läuft, bevor der nächste gestartet wird.
Eine zweite Möglichkeit ist die Erstellung eines neuen Containers, welcher alle benötigten Komponenten enthält. Dies erzeugt allerdings einen höheren Wartungsaufwand, da keine standardisierten Container verwendet werden. Außerdem wird es schwierig, Komponenten auszutauschen (z.B. ein anderes Datenbankmanagementsystem), da dafür der Container neu gebaut werden muss.
Bei beiden Beispielen ist auch das Setup der Intercontainerkommunikation aufwändig, da statische Containerlabels verwendet werden, die von keiner weiteren Anwendung verwendet werden dürfen.
Besser als die beiden oben genannte Beispiele ist es, wenn die Eigenschaften der Betriebsumgebung im Rahmen einer Konfigurationsdatei als Code geschrieben werden. So lassen sich die Komponenten, deren Anzah und Abhängigkeiten sowie die Netzwerkkommunikation einfach festlegen und mit einem Kommando starten oder beenden. Dafür kommen Docker Compose und Podman Compose für Entwicklungsumgebungen und Kubernetes für Integrations- und Produktivumgebungen in Frage.
Docker Compose / Podman Compose
Docker Compose beziehungsweise Podman Compose sind Erweiterungen für Docker und Podman, mit der eine Multi-Container Umgebung als Code definiert und ausgeführt werden kann. Die Definition der Umgebung erfolgt dabei über eine YAML-Datei (z.B. docker-compose.yml). Für jeden Service, also Container, kann dabei unter anderem festgelegt werden:
- Service-Alias
- Zugrundeliegendes Image oder Build-Anleitung
- Anzahl der Container pro Service
- Persistente Volumes (Storage)
- Netzwerk-Ports
- Startreihenfolge (Abhängigkeiten)
Aufbau
Die folgende Abbildung zeigt den grundsätzlichen Aufbau einer Docker / Podman Compose Umgebung.
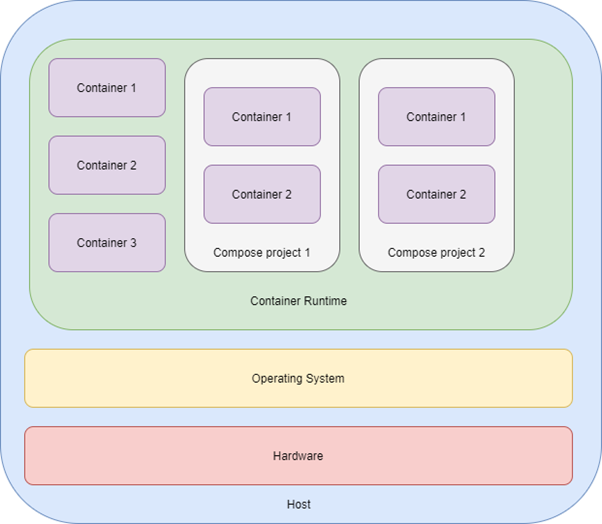
Blau stellt den Host selbst mit seiner Hardware (rot) dar. Auf der Hardware läuft das Host-Betriebssystem (gelb), auf dem wiederum die Container Runtime (grün) wie zum Beispiel Docker oder Podman läuft. Im klassischen Kontext läuft jeder Container (violet) für sich. Docker / Podman Compose kapseln die Container nochmal in unabhängige Projektumgebungen, die parallel zueinander laufen können.
Konfiguriert werden die Compose-Projekte über eine YAML-Datei die nachfolgend beschrieben wird.
docker-compose.yml
Docker Compose und Podman Compose verwenden dasselbe Dateiformat. Daher gelten alle Aussagen, die im weiteren Verlauf getroffen werden, für beide Dienste und es wird daher kurz von Compose gesprochen. Compose ist vor allem für lokale Entwicklungsumgebungen geeignet, da alle Container auf nur einem Host laufen. Dies ist für Produktionsumgebungen mit hoher Last oder mit dem Bedarf nach Ausfallsicherheit (Redundanz) meist nicht ausreichend. Hier sollte auf geclusterte Container-Technologien wie Kubernetes oder Openshift zurückgegriffen werden, auf die später im Artikel noch eingegangen wird.
Im Folgenden findet sich ein Beispiel für eine Docker/Podman Compose Datei:
version: "3"
services:
webserver:
build: .
ports:
- "8080"
depends_on:
- "database"
deploy:
replicas: 2
database:
image: postgres:9.6.23
environment:
- "POSTGRES_PASSWORD=abc#123!"
volumes:
- "./postgres-data:/var/lib/postgresql/data"version beschreibt die verwendete Compose-Version. Je nach Version können verschiedene Schlüsselwörter zur Verfügung stehen.
services leitet die Definition der zu erzeugenden Container ein. Unter dem Servicenamen können die einzelnen Container miteinander in Kontakt treten. Compose erzeugt dazu ein „internes“ Netzwerk zwischen den Containern. In diesem Fall kann der Webserver über den Hostnamen database auf die Datenbank zugreifen. In einem Compose-Projekt können alle Services untereinander frei kommunizieren.
build beim webserver Service gibt an, dass das Containerimage vor dem Start des Service gebaut wird. Bei einem Webserver hat dies zum Beispiel den Sinn, dass der bereitzustellende Inhalt aus dem aktuellen Entwicklungsstand des Repositories neu erzeugt wird. build . bedeutet, dass ein im gleichen Verzeichnis vorhandenes Dockerfile verwendet wird. Es lässt sich aber auch detaillierter spezifizieren, indem das Dockerfile und Verzeichnis explizit angegeben wird.
ports gibt an, welche Ports nach außen für den Host, auf dem Docker läuft, freigeben werden. In dem Fall kann im Browser dann zum Beispiel mit localhost zugegriffen werden. Standardmäßig kann auf die Services innerhalb einer Containerumgebung vom Host aus nicht zugegriffen werden. Für den Service database ist in diesem Beispiel kein Port angegeben, die Datenbank wird also von Host nicht erreichbar sein. Dies liegt darin begründet, dass nur der Webserver auf die Datenbank zugreifen muss und die Services ohnehin, wie bereits erwähnt, frei aufeinander zugreifen können. Aus Debugging-Zwecken kann es natürlich trotzdem sinnvoll sein, die Datenbank auch für den Host direkt freizugeben.
depends_on beschreibt Abhängigkeiten zu anderen Services. Dabei werden die Servicenamen als Liste untereinandergeschrieben. Ein Service startet erst, wenn die anderen Services laufen. Dies schließt auch ein eventuell notwendiges Docker-Build ein. Wichtig ist hier zu wissen, dass nur auf den Start des Servicecontainers gewartet wird. Die darin laufende Applikation kann viel länger für die Initialisierung brauchen bis sie bereit ist, Anfragen von außen zu beantworten. Daher sollte eine Anwendung so geschrieben sein, dass sie die Verwendung eines externen Service entsprechend robust und flexibel abbildet.
Mit deploy können Eigenschaften des Deployments festgelegt werden. Zum Beispiel zugewiesene Ressourcen oder, wie in dem Beispiel, mit replicas die Anzahl der Container, die für diesen Service gestartet werden sollen.
image im Service database legt das konkrete Container-Image fest, dass verwendet werden soll. Es wird also nicht wie im Service webserver erst durch Docker zur Laufzeit gebaut. Es folgt der für (Docker-)Images üblichen Namenskonvention, wie sie auch für docker pull verwendet wird:
<registry>/<image name>:<image tag>
Wird keine Registry angegeben, wie in diesem Beispiel, wird die Default-Registry verwendet. Dies ist meist Docker Hub.
Mit environment können Umgebungsvariablen innerhalb des Containers definiert werden. Dies wird häufig verwendet, um dynamische Aspekte der Konfiguration der Anwendung innerhalb eines Containers zu steuern.
Abschließend enthält das Beispiel noch das Element volumes, mit dem Verzeichnisse aus dem lokalen Dateisystem in den Container eingebunden werden können. Damit können Daten über den Container-Neustart persistiert werden. So wie hier der Inhalt der Datenbank.
Hier finden Sie eine vollständige Beschreibung der Syntax einer docker-compose Datei.
Starten und Stoppen von Compose-Umgebungen
Die beiden wichtigsten Kommandos für das Starten und Stoppen von Compose-Umgebungen sind docker-compose up und docker-compose down beziehungsweise podman-compose up und podman-compose down. Werden keine weiteren Parameter angegeben, so wird im aktuellen Verzeichnis die Konfigurationsdatei docker-compose.yml verwendet. Mit -f lässt sich eine beliebige Datei verwenden, wenn zum Beispiel für verschiedene Umgebungskonfigurationen verschiedene YAML-Dateien verwendet werden.
Mit dem Parameter -d werden die Container im Detached Modus, also im Hintergrund gestartet. Damit lässt sich verhindern, dass beim Schließen der Konsole auch die Services beendet werden.
Sind in der Compose Datei-Abhängigkeiten mit depends_on definiert, startet/baut Compose die Container in der entsprechenden Reihenfolge. Beim Herunterfahren geschieht dies in umgekehrter Reihenfolge.
Ein wichtiges Merkmal von Compose ist es, dass bei einer Änderung der Umgebungskonfiguration in der YAML-Konfigurationsdatei mit docker-compose up nur die Container neu gestartet werden, deren Konfiguration geändert wurde.
Kubernetes
Wie zuvor beschrieben, eignet sich Compose vor allem für lokale Entwicklungs- und Testumgebungen, bei denen es wichtig ist, dass Zusammenspiel der Service-Komponenten abzubilden, ohne auf Ansprüche für Produktivumgebungen wie Skalierbarkeit, Ausfallsicherheit oder Performance einzugehen.
Hier kommt Kubernetes ins Spiel. Dabei handelt es sich um eine skalierbare Containerumgebung, die auf eine Entwicklung von Google zurückgeht. Features beinhalten unter anderem
- Clusterarchitektur verteilt über mehrere Hosts
- Automatische Verteilung der Pods innerhalb eines Kubernets-Clusters
- Dynamische Skalierung der Pods eines Deployments, zum Beispiel abhängig von der aktuellen Auslastung
- Health Checks mit automatischem Neustart der Pods
Aufbau
In der folgenden Abbildung ist der Aufbau eines Kubernets-Clusters (violet) dargestellt. Dieser kann mehrere Host-Systeme überspannen. Einzelne Container können dabei über ihre Kubernetes-Projekte beziehungsweise Namespaces (helles, dunkles rot) bestimmte Ressourcen (CPU, RAM, Storage) anfordern. Kubernetes kümmert sich dann um die Verteilung auf die einzelnen Hosts.
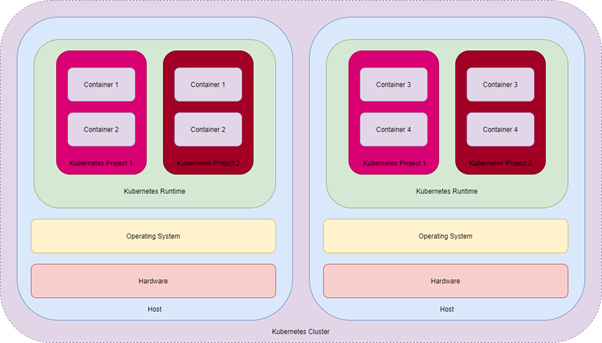
In einer Kubernetes-Umgebung müssen alle Container über Projekte laufen. Unabhängige Container wie bei Docker gibt es hier nicht.
Konfiguration
Durch den größeren Funktionsumfang von Kubernetes (z.B. in Bezug auf Skalierung, Verteilung, Ressourcen) kann in diesem Artikel nur ein einfaches Beispiel einer Grundkonfiguration genommen werden. Dabei wird gezeigt, wie die Umgebung aus dem Beispiel mit Compose in ähnlicher Weise in Kubernetes umgesetzt werden kann.
Kubernetes verwendet wie Compose auch YAML als Dateiformat. Aufgrund der höheren Komplexität werden allerdings mehrere Dateien für die verschiedenen Aspekte (z.B. Deployments, Netzwerk) benötigt. Ein Minimum für einen von außen zugänglichen Service stellt dabei das Deployment, der Service und der Ingress dar, welche nachfolgend beschrieben werden.
Deployment
Container in Kubernetes können nur über sogenannte Pods erzeugt werden, welche wiederum laut Empfehlung nur über Controller angelegt werden sollten. Ein Beispiel dafür sind sogenannte Deployments. Mit Deployments können die auszuführenden Pods mit einem deklarativen Ansatz (Konfiguration der Zieleigenschaften) beschrieben werden. Das folgende Beispiel zeigt den Rollout eines Webservers analog zu dem Beispiel in Compose. Hier wird allerdings ein fertiges Image genommen, da Kubernetes selbst keine Container bauen kann. Mit OpenShift ist dies wiederum möglich.
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpd-deployment
labels:
app: httpd
spec:
replicas: 2
selector:
matchLabels:
app: httpd
template:
metadata:
labels:
app: httpd
spec:
containers:
- name: httpd
image: httpd:latest
ports:
- containerPort: 8080Beim Aufbau der Datei erkennt man einige Gemeinsamkeiten zu Compose (z.B. replicas, ports, image), aber auch Unterschiede – vor allem im Bezug auf Metainformationen. Diese ermöglichen es, über Filterkriterien die Objekte später bei umfangreichen Installationen besser zu identifizieren. Ein paar wichtige Eigenschaften des oben gezeigten Beispiels werden nachfolgend kurz erklärt.
Mit kind wird die Art des zu erzeugenden Objekts der Datei beschrieben. In diesem Beispiel Deployment. metadata/name weist dabei dem Objekt einen Namen zu. Mit metadata/labels können weitere Eigenschaften mit Key/Value-Paaren definiert werden. Üblich ist wie in diesem Beispiel, app um alle zu einer Applikation gehörenden Objekte zu gruppieren. Label sind vor allem auch für die Verknüpfung zwischen den einzelnen Objekten notwendig. So wird die Zuordnung von Services zu Pods über die Label durchgeführt. Eine Beschreibung zu Services befindet sich im weiteren Verlauf dieses Beitrags.
Unter spec erfolgt die Spezifikation des Deployment-Objektes. Zum Beispiel die Anzahl (replicas) der auszuführenden Instanzen. spec/template definiert die Container, die im Rahmen des Deployments gestartet werden sollen. In unserem Beispiel ein Apache Webserver.
Da die Container eine Liste sind, wäre es möglich, auch den Datenbank-Server aus dem Compose-Beispiel in dieses Deployment aufzunehmen. Es macht aber Sinn, dafür ein eigenes Deployment zu verwenden, weil die Anzahl der Replicas nicht pro Container festgelegt werden kann und sie sich innerhalb des Pods auch denselben „Life-State“ teilen. Daher würde man bei einer Erhöhung der Replicas immer sowohl Webserver als auch Datenbank hinzufügen und im Fehlerfall auch beide neu starten. Daher kommt nachfolgend die Deployment-Spezifikation für die Datenbank analog zum Compose-Beispiel.
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
labels:
app: postgres
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:9.6.23
ports:
- containerPort: 5432
env:
- name: POSTGRES_PASSWORD
value: abc#123!
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: postgres-data
volumes:
- name: postgres-data
hostPath: /usr/share/postgres-dataDieses Beispiel zeigt den Umgang mit Umgebungsvariablen (env) und der Einbindung eines persistenten Speichers (volumes) für die Daten der Datenbank.
Im Gegensatz zu Compose lassen sich mit Kubernetes keine Abhängigkeiten zwischen den Pods definieren. Dies ist allerdings kein großer Nachteil, da – wie bereits beschrieben – Compose auch nur auf das Laufen des Containers wartet und nicht die Bereitschaft der Applikation. Daher muss der Umgang mit (noch) nicht vorhandenen Ressourcen als Teil der Applikation implementiert werden.
Nachdem die Deployments eingerichtet sind, folgt noch die Einrichtung der Netzwerkverbindungen durch Services und Ingresses.
Service
Da Pods in Kubernetes einer hohen Dynamik mit ständig wechselnden internen IP-Adressen unterliegen, werden diese durch (DNS-) Services unter einem gemeinsamen Alias im internen Netzwerk des Kubernetes-Projektes zur Verfügung gestellt. Kubernetes kümmert sich um die korrekte Zuordnung der Pods zum Service und das Routing im Netzwerk inklusive zum Beispiel des Load Balancing. Der Webserver greift dann auf die Datenbank über den entsprechenden Servicenamen als Hostnamen zu. In diesem Beispiel werden zwei Services gebraucht.
apiVersion: v1
kind: Service
metadata:
name: httpd-service
spec:
selector:
app: httpd
ports:
- protocol: TCP
port: 8080
---
apiVersion: v1
kind: Service
metadata:
name: postgres-service
spec:
selector:
app: postgres
ports:
- protocol: TCP
port: 5432Das Beispiel weist dem Webserver den Servicenamen httpd-service zu und der Datenbank den Namen postgres-service. Der Webserver kann nun über den Hostnamen postgres-service auf die Datenbank zugreifen. Die Zuordnung der Services zu den entsprechenden Pods geschieht über den spec/selector, der auf den in den Deployments festgelegten Selektoren basiert.
In diesem einfachen Beispiel wird ein Service vom Typ ClusterIP verwendet, welcher der Default ist, wenn es nicht speziell angegeben wird. Damit ist der Service nur innerhalb des Kubernetes-Clusters mit <service-name> oder <service-name>.<namespace> erreichbar. So kann noch nicht über einen Browser von außen auf den Webserver zugegriffen werden. Dafür wird ein sogenannter Ingress (engl. für Zugang) benötigt, welcher im nächsten Abschnitt beschrieben wird.
Ingress
Mit einem Ingress kann der Zugang von außen auf einen Service eingerichtet werden. Primär bezieht sich dies auf das HTTP- und HTTPS-Protokoll. Dies hat damit zu tun, dass Kubernetes über einen Ingress als Reverse-Proxy auftritt und das Routing über die im HTTP-Header enthaltene URL durchführt. Für andere Protokolle ist dies schwieriger, da das Ziel unter Umständen nicht aus dem Protokollheader hervorgeht. Es gibt zwar auch hier Möglichkeiten, diese gehen aber über den Inhalt dieses Artikels hinaus.
Für einen Ingress auf den Webserver ist die nachfolgende Konfiguration zuständig.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: http-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /app-path
pathType: Prefix
backend:
service:
name: httpd-service
port:
number: 8080Darüber wird der Zugriff auf <kubernetes-host>/app-path auf den Service httpd-service und darüber auf den entsprechenden Pod umgeleitet. In der nachfolgenden Darstellung sind die Kommunikationsbeziehungen über das gesamte Kubernetes-Beispiel dargestellt.
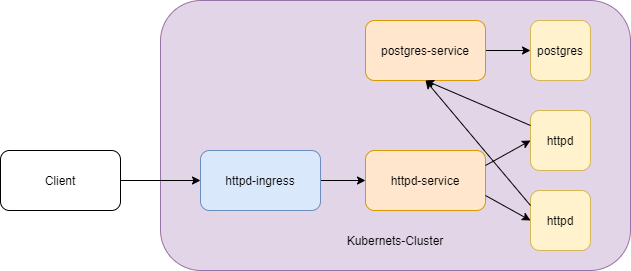
Rollout
Sind alle oben genannten Konfigurationsdateien (Deployment, Service, Ingress) vorhanden, so lassen sich diese über einen vorhandenen Kubernetes-Kommandozeilenclient schnell ausrollen. Mit
kubectl apply -f *.yml
lassen sich alle im gegenwärtigen Verzeichnis befindlichen YAML-Dateien gemeinsam deployen. Ist die betreffende Ressource nicht vorhanden, wird sie angelegt. Ist sie vorhanden, wird sie aktualisiert. Mit
kubectl delete -f *.yml
werden die Objekte wieder entfernt.
Hier gelangen Sie zu einer weiterführenden Dokumentation des Kubernetes-Kommandozeilenclients.
Zusammenfassung
Wie dargestellt, lassen sich mit Compose und Kubernetes komplexe Applikationslandschaften mit wenigen Zeilen „Code“ definieren und mit wenigen Kommandos zügig ausrollen, ohne manuell einzelne Docker/Podman Container hoch- und runterzufahren. Der Code lässt sich zudem zusammen mit der entwickelten Applikation in einem gemeinsamen Code-Repository ablegen, so dass die Applikationslogik und die Betriebsumgebung gemeinsam entwickelt werden können.
So wird es auch jedem Projektbeteiligten ermöglicht, die Anwendung in gleicher Form bei sich zu Test- oder Betriebszwecken zu deployen und auszuführen. Darüber hinaus lässt sich das Konstrukt über mehrere Stages in einer voll automatisierten DevOps-Pipeline einsetzen.
Compose eignet sich vor allem für Entwicklungsumgebungen, da die Container auf einen Host (Ausnahme über Docker Swarm) gebunden sind. Kubernetes, mit seinen Cluster-Möglichkeiten und komplexen Konfigurationsmöglichkeiten, zielt eher auf Integrations- und Produktionsumgebungen ab.

