
Seit vielen Jahren setzen zahlreiche Unternehmen wie Amazon oder Google auf Containertechnologie, um ihre Dienste up-to-date und stets verfügbar zu halten. Das rasche Ausrollen von Aktualisierungen, eine verbesserte Lastverteilung durch bei Bedarf sekundenschnell skalierbare Infrastruktur sowie ein sofortiges und automatisches Neustarten im Falle eines Dienstabsturzes wird durch diese Technologie ermöglicht. Doch was auf dem Papier gut klingt, kann in der Praxis mitunter schwer umsetzbar sein.
Wir widmen uns in diesem Beitrag den Herausforderungen, indem wir stateful- und stateless-Applikationen erklären, die Unterschiede verdeutlichen und zeigen, wie es in Projekten genutzt werden kann.
Als Beispiel dient uns eine Applikation mit zwei Containern, deren Last über einen Loadbalancer verteilt wird. Häufig ist es so, dass ein User auf den Loadbalancer zugreift, und dieser leitet ihn an Server 1 weiter. Dort loggt er sich ein, erzeugt damit eine Session und führt weitere Aktionen aus. Nach einigen Minuten will er weitere Funktionen ausführen, doch diesmal leitet ihn der Loadbalancer jedoch an Server 2 weiter. Die Erwartungshaltung des Users ist es, dass die Session weiter genutzt werden kann. Server 2 kennt sie aber nicht, da sie nur im Speicher von Server 1 erzeugt wurde. Daher müsste sich der User erneut einloggen.
Ein weiteres Beispiel ist eine Applikation, die Arbeitsdaten im Speicher hält und durch Benutzerinteraktionen verändert wird. Wenn der Dienst nun abstürzt und neu startet, sind die Daten im Speicher verloren und der User muss die Aktionen unter Umständen wiederholen.
Stateless vs. Stateful
Die oben genannten Beispiele zeigen, wie wichtig es bei Container-Applikationen ist, zwischen stateless (zustandslos) und stateful (zustandsbehaftet) zu unterscheiden. Dazu wird in diesem Abschnitt der Unterschied zwischen beiden Eigenschaften erörtert.
Eine zustandslose Anwendung enthält keine Daten, die zur Laufzeit einer Veränderung unterliegen. Ihr Verhalten ist daher festgelegt – die gleichen Eingaben führen immer zum gleichen Ergebnis. Ein einfaches Beispiel ist in Abbildung 1 ein Service zur Addition zweier Zahlen.
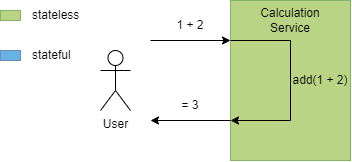
Ein Service ist auch dann zustandslos, wenn er seinerseits auf externe Services zugreift, diese intern aber immer gleich verarbeitet werden und nicht auf einen Vorzustand angewiesen ist. Dies kann etwa eine Webapplikation sein, die das Wetter anzeigt und die Wetterdaten von einem externen Service bezieht.
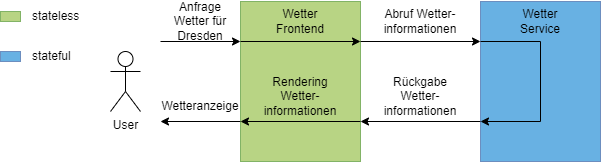
Es gibt auch Sonderfälle wie nicht-deterministische Antworten durch die Verwendung von Zufallsgeneratoren oder veränderliche innere Zustände durch Caching. Diese können allerdings auch als stateless betrachtet werden, wenn davon auszugehen ist, dass ein ungeplanter Neustart des Containers keine Auswirkung auf die zukünftige Verarbeitung hat.
Stateful Applications hingegen haben veränderliche Daten, die eine Auswirkung auf zukünftige Ergebnisse haben. Beispiele sind hier HTTP-Sessions, ein intern gespeicherter Warenkorb oder Produktdaten in einer Datenbank.
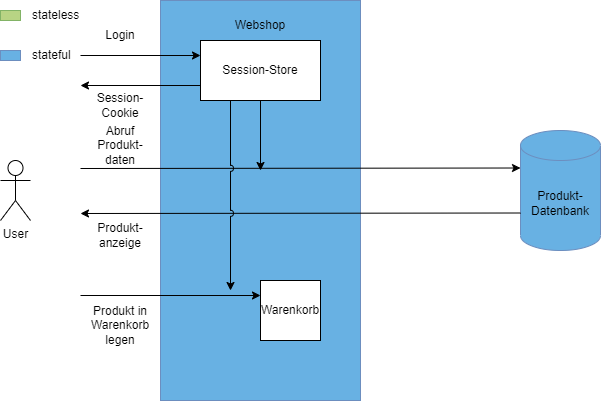
In Abbildung 3 sind der Webshop und die Produktdatenbank zustandsbehaftete Services. Der Webshop speichert die HTTP-Session, damit sich der User nicht bei jeder Aktion neu einloggen muss. Außerdem enthält er einen Warenkorb, der zur Laufzeit die gewünschten Bestellungen enthält. Die Produktdatenbank wiederum enthält die Information zu den angebotenen Produkten, den Warenbestand und die Preise. Wenn die Zustände nicht gesichert werden, sind die Daten nach einem Container-Neustart nicht mehr vorhanden.
Je Stateless desto besser
Der große Vorteil zustandsloser Anwendungen liegt in der nahezu unbegrenzten Skalierbarkeit der Anwendung. Bei einem vorgeschalteten Loadbalancer (LB) ist es aus der Sicht des Users egal, ob er beim nächsten Aufruf auf einem anderen Knoten derselben Anwendung landet, denn das Ergebnis wird dasselbe sein. Unter dieser Maßgabe ist die Anwendung aus Abbildung 3 auch nicht optimal, da der User durch den LB auf einem anderen Knoten landen kann und sich damit neu einloggen muss und der Warenkorb leer ist.
Es ist also wichtig, dass schon im Rahmen der Anwendungsarchitektur die zustandslosen und zustandsbehafteten Anteile sauber getrennt werden. Abbildung 4 zeigt eine Möglichkeit, wie die Anwendung in Abbildung 3 besser implementiert werden kann.
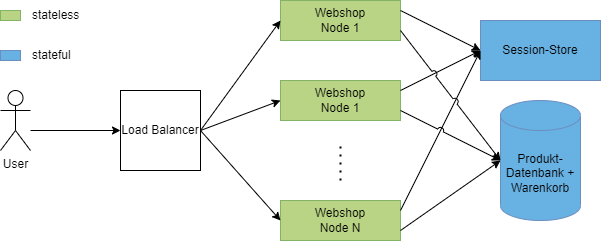
Eine saubere Abtrennung der zustandsbehafteten Anteile ist auch deswegen wichtig, da dies meist jene Bestandteile sind, die im besonderen Maße vor Datenverlust gesichert werden müssen. Gerade bei den in Abbildung 4 dargestellten Produktdaten wäre es fatal, wenn die Daten nach einem Neustart verloren sind.
Das Beispiel zeigt auch, dass bei beliebiger Skalierung des Webshops irgendwann der Session-Store und die Produkt-Datenbank zum Flaschenhals werden. Hier ist also auch eine Skalierung notwendig. Die Herausforderung dabei ist, die Daten synchron zur Verfügung zu stellen. Für die besonderen Anforderungen an zustandsbehaftete Services stellt Kubernetes das sogenannte StatefulSet zur Verfügung. Was das ist und wie es sich von einem Deployment unterscheidet, wird im Kapitel „Kubernetes Deployments und StatefulSets“ weiter unten beschrieben.
State ist nicht gleich State
Der Vollständigkeit halber ist noch zu sagen, dass die Notwendigkeit zur Sicherung des Zustands von den enthaltenen Daten abhängig ist. Es ist zwar ärgerlich, wenn der Session-Store aus Abbildung 4 zurückgesetzt wird und man sich neu einloggen muss, aber das ist eher nur eine kleine Unpässlichkeit. Auch die Warenkorbdaten sind verschmerzbar. Die Produktdatenbank hingegen kann einen wesentlichen Bestandteil eines Unternehmens ausmachen und ist daher besonders kritisch.
Auch ist die Art der Daten ist entscheidend für die Architektur. Der Session-Store enthält eher viele kleine Datensätze mit begrenzter Gültigkeit, die sehr häufig – zum Beispiel bei jedem Request – gelesen werden. Hier eignet sich eher eine schnelle In-Memory Datenbank wie Redis. Die Produktdaten hingegen werden seltener gelesen, unterliegen aber unter Umständen komplizierteren Suchabfragen und müssen auch langfristig gesichert werden. Hier eignet sich dann eher eine richtige Datenbank wie zum Beispiel MySQL.
Kubernetes Deployments und StatefulSets
Im einfachsten Fall ist für die Persistenz des Zustands einer Anwendung ein PersistentVolume (PV) ausreichend. Ein PV ist ein Teil des Speichers im Cluster, der von einem Administrator bereitgestellt oder dynamisch bereitgestellt wurde. Damit können die veränderlichen Bestandteile auf einen festen Storage ausgelagert werden und überleben damit einen Pod-Neustart. Viele Image-Beschreibungen auf Docker Hub weisen die notwendigen Pfade aus. Ein Pod ist eine Gruppe von einem oder mehreren Containern mit gemeinsamen Speicher- und Netzwerkressourcen und einer Spezifikation für den Betrieb der Container.
Ein Problem ergibt sich dann, wenn die Anzahl der Pods skaliert werden muss. Damit jeder Pod dieselben Daten vorhält müssen sie sich untereinander synchronisieren. Dabei reicht es in den seltensten Fällen aus, einfach auf denselben Speicher zu schreiben. Bei einer Datenbank führt das unweigerlich zu Inkonsistenzen, wenn mehrere Dienste gleichzeitig schreiben. Auch müssen sich die Pods eines Service untereinander finden, damit sie Daten austauschen können.
Für diese besonderen Belange stellt Kubernetes das sogenannte StatefulSet zur Verfügung. Folgend sind die Hauptunterschiede zwischen einem Deployment, dem Normalfall für zustandslose Anwendungen und einem StatefulSet beschrieben.
Ein Deployment bietet deklarative Updates für Pods durch Beschreibung eines gewünschten Zustands und der Bereitstellungscontroller ändert den IST-Zustand kontrolliert in den gewünschten SOLL-Zustand. Ein StatefulSet ist ein Objekt, das zur Verwaltung zustandsabhängiger Anwendungen verwendet wird. Es verwaltet die Bereitstellung und Skalierung eines Satzes von Pods und bietet Garantien für die Reihenfolge und Einzigartigkeit dieser Pods.
Hauptmerkmale Deployment:
- Pods sind identisch und austauschbar
- sie werden in zufälliger Reihenfolge erzeugt und terminiert
- der Suffix eines Pods erhält einen zufälligen Hashwert
- Services verbinden einen Aufruf an einen zufälligen Pod unter demselben Hostnamen
- Pods haben Zugriff auf einen gemeinsamen Storage
Hauptmerkmale StatefulSets:
- Pods werden auf Grundlage derselben Spezifikation erzeugt, sind aber nicht identisch
- die Podnamen erhalten einen festen Suffix der von 0 aufwärts zählt (z.B. <set-name>-0, <set-name>-1, …, <set-name>-n)
- die Erzeugung neuer Pods erfolgt in aufsteigender numerischer Reihenfolge (0, 1, …, n), die Terminierung in umgekehrter Reihenfolge (n, …, 1, 0)
- Pods haben keinen Zugriff auf einen gemeinsamen Storage
- die Hostnamen im Service sind fest an die Podnamen gebunden, es findet keine Lastverteilung statt
Die besonderen Eigenschaften des StatefulSets sind wichtig, damit jeder Pod immer dieselbe Rolle (z.B. Primary, Replicas) durch denselben Storage und denselben Hostnamen erhält. Wichtig zu wissen ist, dass Kubernetes mit dem StatefulSet und dessen besonderen Eigenschaften nur den Rahmen für eine Anwendung schafft, die ihren Zustand untereinander synchronisieren muss. Ob die Applikation dazu in der Lage ist und wie es eingerichtet werden muss, hängt dann von ihr ab.
Warum StatefulSets am Beispiel MySQL
Im Folgenden wird beschrieben, warum für einen Service wie MySQL ein StatefulSet notwendig ist. Im einfachsten Fall existiert nur ein Pod für die MySQL-Datenbank. Dies ist in Abbildung 5 dargestellt. Wie bereits erwähnt würde dafür ein Kubernetes Deployment ausreichen, so lange die Anzahl der Replicas auf 1 verbleibt.

Soll die Anzahl der MySQL-Instanzen allerdings erhöht werden, funktioniert dies nicht, da es sonst zu Inkonsistenzen kommt, wenn in dasselbe PV geschrieben wird. Im Fall von MySQL darf nur eine Instanz schreiben aber mehrere können lesen.
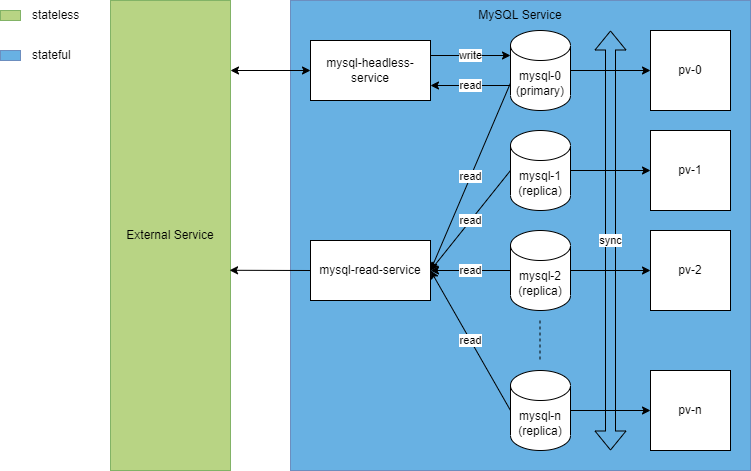
Abbildung 6 zeigt einen MySQL-Cluster mit StatefulSets. Es gibt einen Primary Server (mysql-0) der lesen und schreiben darf und die Replicas, von denen nur gelesen werden darf. Da die Pods eines StatefulSets beginnend mit 0 initialisiert werden, ist sichergestellt, dass der Primary Node immer unter diesem Hostnamen mit dem dazugehörigen PV initialisiert wird. Damit sich mysql-0 als Primary Server initialisiert, muss durch entsprechende Skripte beim Start des Pods abhängig vom Hostnamen mit Suffix =0 die entsprechende Konfiguration herangezogen werden. Gleiches gilt dann entsprechend für die Pods mit Suffix >0. Dieser Teil ist von der jeweilig verwendeten Applikation abhängig und kann daher nicht durch Kubernetes bereitgestellt werden. Das betrifft auch die Synchronisation der Pods untereinander.
Wichtig sind außerdem noch die zwei Services mysql-headless-service und mysql-read-service. Der mysql-headless-service stellt dabei für jeden der Pods des StatefulSets den jeweilen DNS-Namen, also mysql-0 bis mysql-n, zur Verfügung. So kann mit mysql-0 immer auf den Primary geschrieben werden. Der mysql-read-service stellt dann als normaler load balanced-Service jeden Pod zentral zum Lesen bereit. Daraus leitet sich auch ab, dass in externen Applikationen, welche die Datenbank nutzen, explizit zwischen schreibenden und lesenden Verbindungen unterschieden werden muss. Das muss bei der Implementierung entsprechend berücksichtigt werden. Diese explizite Trennung betrifft auch nicht zwangsläufig jeden Service, den man betreibt. Es gibt auch Dienste, wie zum Beispiel Elasticsearch, die sich selbstständig um ihre Synchronisation kümmern können und dies daher von außen völlig transparent machen.
Fazit
Dieser Beitrag hat gezeigt, wie wichtig es ist zwischen zustandsbehafteten (stateful) und zustandslosen (stateless) Services zu unterscheiden. Dies wird vor Allem dann relevant, wenn lastbedingt skaliert werden soll. Container- und Cloud-Technologien sind in besonderem Maße für zustandslose Services geeignet, da diese beliebig skaliert werden können. Da aber die wenigsten Applikation ohne eine Persistenz des Zustands auskommen, stellt Kubernetes mit dem StatefulSet einen Rahmen zu Verfügung, solche Dienste zu betreiben.
Für eine möglichst hohe Effizienz ist dabei auch schon im Vorfeld bei der Lösungsarchitektur eine saubere Trennung zwischen den stateless- und stateful-Anteilen durchzuführen. Die stateful-Anteile sollten dabei auch entsprechend der Daten, die sie beinhalten werden (zum Beispiel HTTP-Session oder Produktdaten) konzipiert werden.

